首页
/ 技术专题
/ ETL
/ 阿里云开源离线同步工具DataX3.0,或成未来数据库同步主流工具
阿里云开源离线同步工具DataX3.0,或成未来数据库同步主流工具
DataX3.0简介
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
本次介绍为阿里云开源全新版本DataX3.0,有了更多更强大的功能和更好的使用体验。
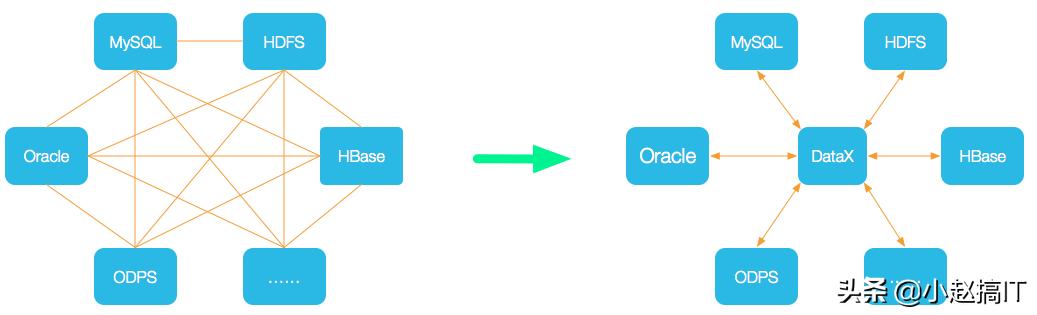
DataX3.0概览
设计理念 与 框架设计
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: 为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。

框架设计
DataX3.0 插件体系
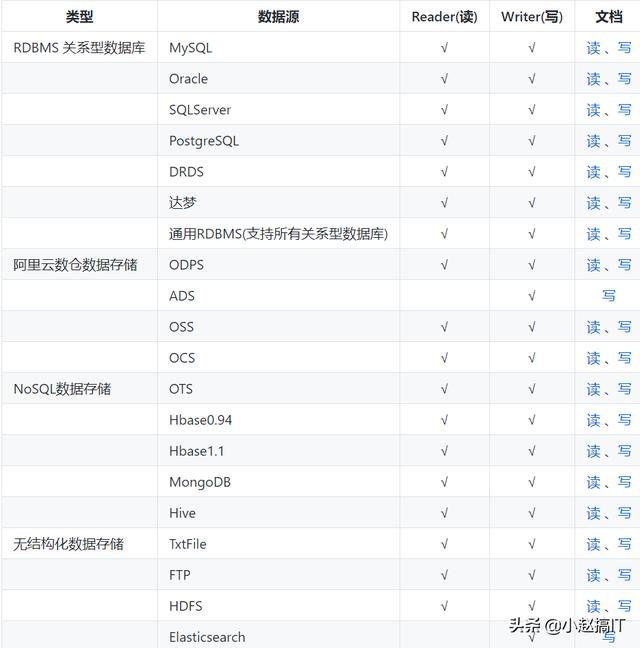
DataX3.0 目前支持数据如下:
DataX3.0 的优势
实现步骤
先说一下需求:
我们有一台测试的mysql数据库上有 cms和appdata 两个库,这两个库里面都有user_msg 这个表,
现在需要把appdata 下面的user_msg表同步到 cms 库下面的user_msg表中,并且要求每分钟同步一次。
分析需求:
1,看到这个需求后,首先排除了mysql主从复制,因为同一个数据库 server_id 相同不能用主从复制。
2,要求每分钟同步一次,如果表的数据量很多很大,那很容易阻塞,所以不能每次全量同步,要用增量同步的方式才行,这里就排除一些手写sql的方式了。
我采用的就是 DataX3.0 ,下面记录了详细步骤:
1,安装
#我的服务器系统是 CentOS7
#这个包有点大,注意磁盘容量
wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
tar xf datax.tar.gz
#看一下目录结构:
[root@VM_0_5_centos ~]# tree -L 2 datax
datax
|-- bin
| |-- datax.py
| |-- dxprof.py
| `-- perftrace.py
|-- conf
| |-- core.json
| `-- logback.xml
|-- job
| `-- job.json
|-- lib
| |-- commons-beanutils-1.9.2.jar
| |-- commons-cli-1.2.jar
| |-- commons-codec-1.9.jar
| |-- commons-collections-3.2.1.jar
| |-- commons-configuration-1.10.jar
| |-- commons-io-2.4.jar
| |-- commons-lang-2.6.jar
| |-- commons-lang3-3.3.2.jar
| |-- commons-logging-1.1.1.jar
| |-- commons-math3-3.1.1.jar
| |-- datax-common-0.0.1-SNAPSHOT.jar
| |-- datax-core-0.0.1-SNAPSHOT.jar
| |-- datax-transformer-0.0.1-SNAPSHOT.jar
| |-- fastjson-1.1.46.sec01.jar
| |-- fluent-hc-4.4.jar
| |-- groovy-all-2.1.9.jar
| |-- hamcrest-core-1.3.jar
| |-- httpclient-4.4.jar
| |-- httpcore-4.4.jar
| |-- janino-2.5.16.jar
| |-- logback-classic-1.0.13.jar
| |-- logback-core-1.0.13.jar
| `-- slf4j-api-1.7.10.jar
|-- plugin
| |-- reader
| `-- writer
|-- script
| `-- Readme.md
`-- tmp
`-- readme.txt
2,生成模板文件 并配置同步
同步需要一个配置文件,我们先生成一个模板文件,然后修改。
我是从mysql读取,再写到 mysql , 所以我的 命令是下面这样:
python datax/bin/datax.py -r mysqlreader -w mysqlwriter
再比如,你要把 mongodb 的数据同步到mysql,生成模板文件的命令就变成了下面这样:
python datax/bin/datax.py -r mongodbreader -w mysqlwriter
#mysqlreader 和 mysqlwriter 分别是mysql的读取和写入插件。
#datax3.0 支持非常多的插件,可以到 datax的github主页了解详情。
有了配置文件之后要按需求修改一下,我修改后是下面这样的:
cat /tmp/test.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ['*'],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://127.0.0.1:3306/appdata"],
"table": ["user_msg"]
}
],
"password": "your-passwd",
"username": "your-username",
"where": ""
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ['*'
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/cms",
"table": ["user_msg"]
}
],
"password": "your-passwd",
"preSql": [],
"session": [],
"username": "your-username",
"writeMode": "update"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
#注意:writeMode 我这里是 update,如果不存在会先创建数据,存在就更新
然后先执行一次全量同步
datax/bin/datax.py /tmp/test.json
3,增量同步并设置定时
配置文件中的 where 参数可以设置一些查询条件,
比如我的表里有一个字段是 create_timestamp ,这个是一个时间戳,
我可以通过这个字段来过滤一个时间段内的新增数据,从而实现增量同步。
修改后我的配置文件是下面这样 :
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ['*'],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://127.0.0.1:3306/appdata"],
"table": ["user_msg"]
}
],
"password": "your-passwd",
"username": "your-username",
"where": "create_timestamp > ${start_time} and create_timestamp < ${end_time}"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ['*'
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/cms",
"table": ["user_msg"]
}
],
"password": "your-passwd",
"preSql": [],
"session": [],
"username": "your-username",
"writeMode": "update"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
# 注意事项,create_timestamp 我这里是int 类型的 。
下面简单写个同步脚本:
cat sync.sh
#!/bin/bash
# 截至时间设置为当前时间戳
end_time=$(date +%s)
# 开始时间设置为120s前时间戳
start_time=$(($end_time - 120))
/root/datax/bin/datax.py /tmp/test.json -p "-Dstart_time=$start_time -Dend_time=$end_time"
#添加定时任务,实现每分钟同步一次
* * * * * sh /root/sync.sh